
← Männer sind mitgemeint | Heuer doch wieder Musica-Viva in Österreich →
TDOSCA & OSCake: FOSS Compliance automatisieren
Mit dem Open Source License Compendium und dem Open Source Compliance Advisor hat die Deutsche Telekom das Thema ‚Open-Source-Compliance‘ bereits vorangebracht. Allerdings bietet die DT mittlerweile so viele komplexe Produkte mit Open-Source-Anteil an, dass es zu teuer wird, die notwendigen Compliance-Artefakte manuell zu erzeugen. Notwendig ist eine praktisch nutzbare automatisierte ‚Toolchain‘. Dieser Artikel disuktiert eine neue Methodik (TDOSCA) und einen neues Tool (OSCake), die die DT unter dem Dach des Open Chain Projekts öffentlich umsetzt.
3 einfache Fragen an Open Source Compliance Tools
Es gibt ohne Zweifel bereits eine Reihe von Open-Source-Compliance tools. Die Open-Chain-Reference-Tooling-Work-Group hat eine entsprechende Liste zusammengestellt. Die kann noch weiter gruppiert werden:
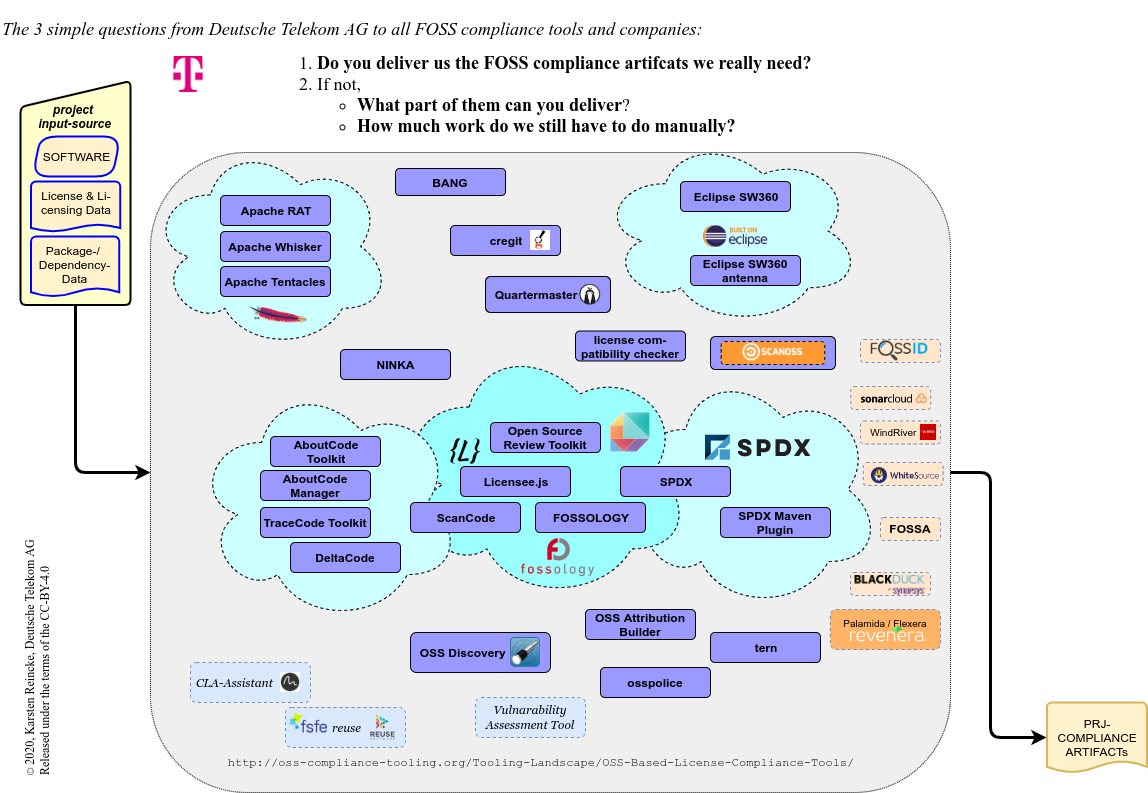
- Einige der Tools werden von Organisationen wie die Apache-Foundation, SPDX, Eclipse der der About-Code-Initiative angeboten.
- Andere stehen insofern etwas abseits, als sie einen speziellen Fokus haben oder gar keine richtige Tools sind.
- Und wieder andere bilden eine Gruppe, weil sie eher Services sind, als Tools.
Die Deutsche Telekom hat dabei einen recht einfachen Blickwinkel. Wann immer ihr ein FOSS-Compliance-Tool begegnet, fragt sie deren Entwickler und ihre Angestellten:
- Liefert dieses Tool der Firma die FOSS-Compliance-Artefakte, die sie wirklich benötigt? Und wenn nicht,
- Welchen Teil davon könnte es ihr liefern?
- Wieviel Handarbeit fällt dann noch auf Seiten der Telekom an?
Die Deutsche Telekom hat viel Erfahrung darin, angebotene FOSS-Compliance-Tools zu sichten. Ihren Angestellten sind exzellente Tools und brilliante Experten begegnet, die oft völlig davon überzeugt waren, dass sie der Firma umfassend helfen könnten. Am Ende der Gespräche fühlte es sich aber oft so an, dass die Anbieter nicht wirklich verstanden hatten, was die DT benötigte (und noch immer benötigt). Um den Punkt zu verdeutlichen: Wer lange Listen gefundener FOSS-Komponenten anbietet und dann sagt, dass die Firma nun jeden Eintrag mit ihren Juristen durchgehen müsse, hilft ihr nicht wirklich.
Und dennoch, auch die Deutsche Telekom AG muss mit solchen langen Listen umgehen. Die Open Source Compliance ist keine Frage der Lust oder Unlust: Entweder man nutzt die Open-Source-Komponenten und erfüllt die Lizenzbedingungen, oder man nutzt die Komponenten nicht. Deshalb kann Telekom auch nicht länger warten. Die Komplexität ihrer Produkte zwingt sie, die Automation von Open-Source-Compliance selbst voranzutreiben. Allerdings wird sie dazu nicht den nächsten Greenfield-Ansatz verfolgen, sondern sich im Geiste von Open-Source-Entwicklungen in bestehende Projekte einbringen.
Eine Test-Driven Entwicklung von Tools zur Erzeugung von Open Source Compliance Artefakten
DTs erster Schritt zielte auf die Verbesserung ihrer eigenen Kommunikation. Sie wollte – ausgehend vom Standpunkt einer großen Firma mit vielen komplexen Softwarestacks – einfacher klarstellen, was sie wirklich benötigt und von Tools erwartet. Zu diesem Zweck hat die Telekom den Ansatz einer ‚Test Driven Software Entwicklung‘ auf die Programmierung der Compliance-Tools übertragen:
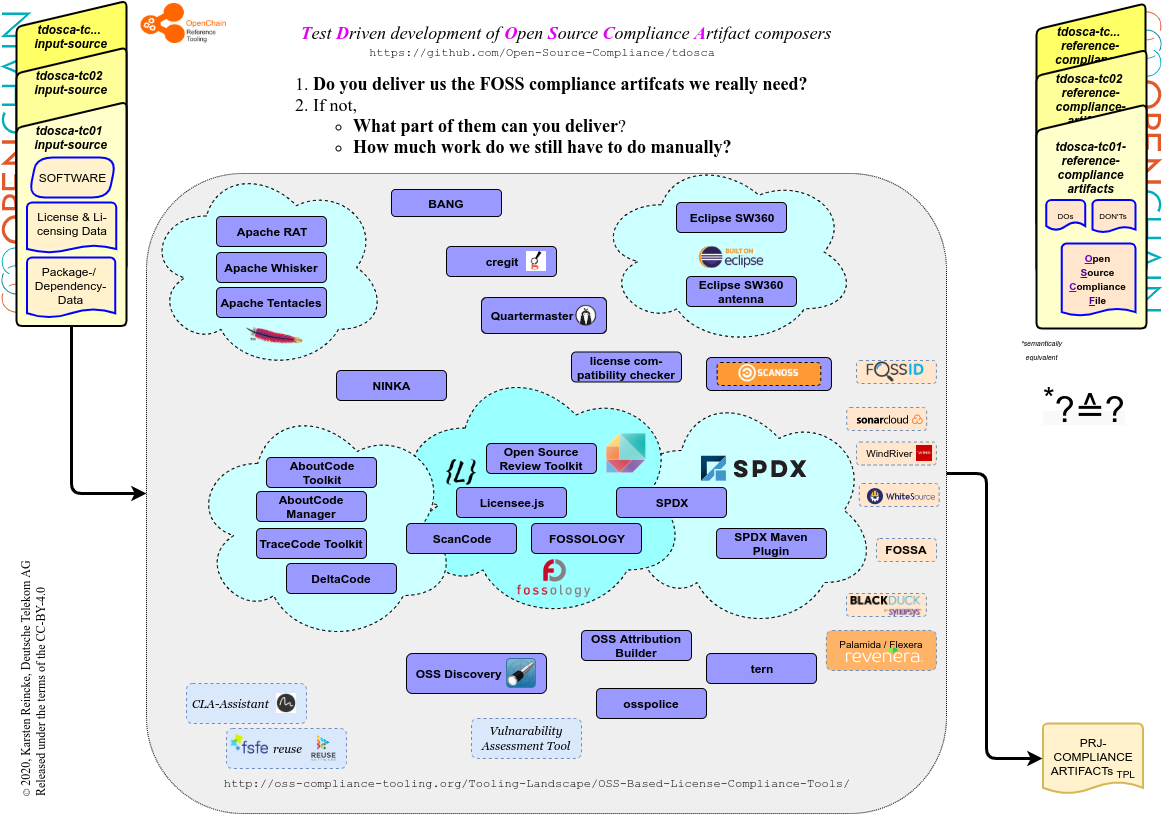
- Einerseits sollen die Testcases wirklich nutzbare Software enthalten, und zwar zusammen mit den Angaben über Lizensierungen und Abhängigkeiten und eingebettet in Paketmanager, wie sie auch in ‚richtigen‘ Open-Source-Projekten verwendet werden.
- Andererseits sollen diese Testcases als Refeenzdaten auch schon alle Compliance-Artefakte enthalten, die es, so man sie dem Softwarepaket hinzufügte, erlauben würden, die paketierte Software lizenzkonform zu verteilen.
Außerdem meint die DT,
- dass existierende Open-Source-Projekte in der Regel zu komplex seien, um um sie zu Testcases zu machen.
- dass ‚künstlich‘ erzeugte Software sich besser auf einzelnen Compliance-Aspekte fokussieren lasse.
- dass die Referenz-Software auf der einen Seite funktional einfache Hello- World Programme sein sollten,
- die auf der anderen Seite auch solche ausgefeilten Compliance-Fallen enthalten müsse, wie man sie in richtigen Open-Source-Projekten findet..
Anhand solcher Test-Cases sollten die Community, die Tools und beteiligte Firmen verifizieren und kommunizieren können,
- welche Compliance-Fallen ein Tool schon erfolgreich bewältigt,
- welche Artefakte ein Tool schon liefert (und welche nicht),
- wo es noch offenen Herausforderungen gibt
- und wo abweichend Ergebnisse nur eine Frage der Interpretation sind.
Die ‚Hello World‘ Open-Source-Compliance-Testcases
Alle TDOSCA-Testcases werden unter dem Dach der GitHub-Organization Open-Source-Compliance gehostet und anhand des Prefixes tdosca gruppiert. Die README-Datei des Hauptrepositories tdosca beschreibt die allgemeine Systematik: Man darf erwarten, dass jeder Testcase dieselbe Struktur mitbringt. Die kann gut anhand des Testcases tdosca-tc06-plainhw erläutert werden:
- Auf der obersten Ebene beschreibt eine spezifische README-Datei die Intentionen des Testcases.
- Im Ordner input-sources befindet sich die Software
- samt der Lizenz und Lizensierungsinformation, die analog zu ‚echten‘ Projekten arrangiert sind
- in einer Form, dass sie mit den Standardtechniken kompiliert und installiert werden könnte (hier also mit java + maven).
- Auf der obersten Ebene beschreibt außerdem eine ‚Compliance-Trap Datei‘ die Herausforderungen, die in und mit diesem Testcases implementiert worden sind und mit denen ein Tool umgehen sollte.
- In dem Ordner reference-compliance-artifacts befinden sich dann die Compliance-Artifakte, die ein Tool idealerweise liefern sollte:
- eine BOM-Datei, die die enthaltenen Komponenten auflistet
- eine Liste der Pakete, die auf dem Zielsystem vorinstalliert sein müssen
- die eine Open-Source-Compliance-Datei, die – sofern man sie dem Paket als Ganzes hinzufügt – daraus ein lizenzkonform distribuierbares Softwarepaket macht.
Die einzelnen Testcases sind in den speziellen Repositories tdosca-tc01 … tdosca-tc0n abgelegt.
Zentrales Element der Referenzartefakte ist die Datei Open Source Compliance File: Zu ihrem Format hat sich die Deutsche Telekom von einer Datei inspieren lassen, die Cisco OSCF dem Jabber-Client beilegt: https://www.cisco.com/c/dam/en_us/about/doing_business/open_source/ docs/CiscoJabberforWindows-128-1578365187.pdf. Diese Datei ist nicht perfekt. Aber zeigt gut, wie man mit dem Thema umgehen könnte. Im Rahmen von TDOSCA bietet die OSCF-Datei des 6. Testcases einen guten Einblick.
Ein Zwischenfazit und ein Zusatz:
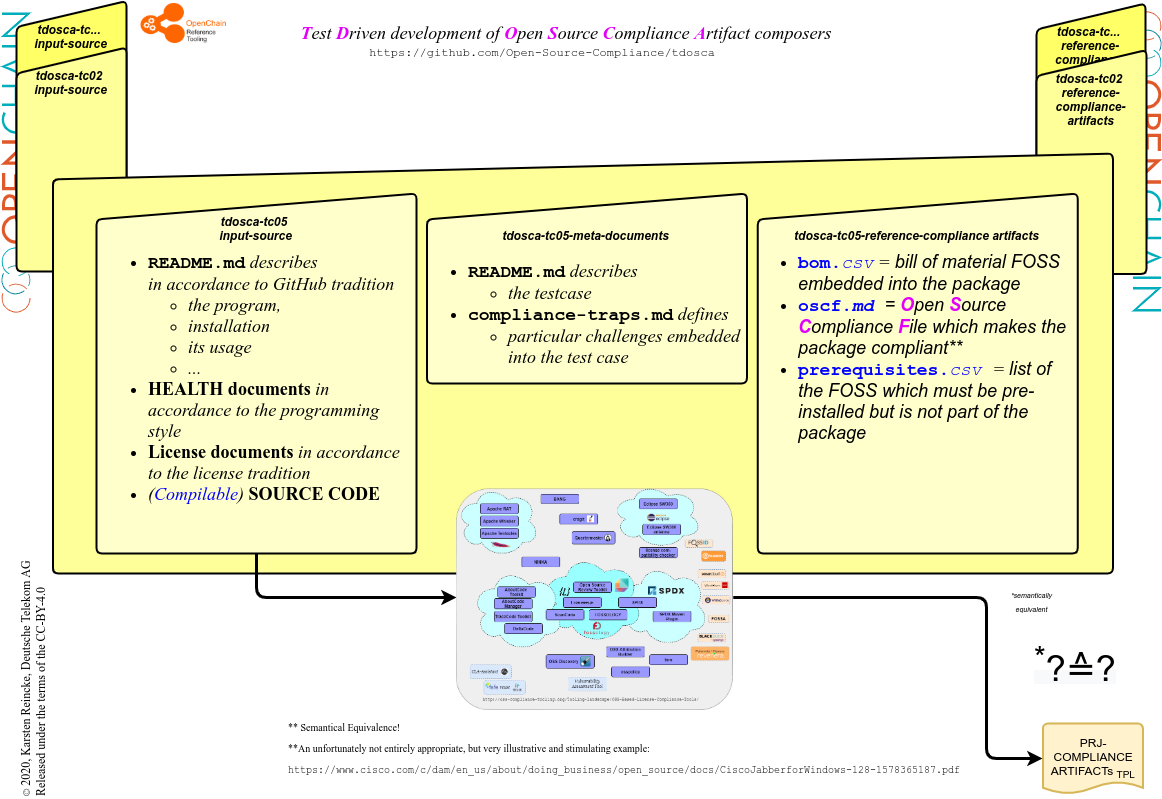
Im allgemeinen nutzen die TDOSCA-Testcases also die folgende Struktur:
Die TDOSCA-Intiative – gehosted unter dem Schutz des Open-Chain-Projektes der Linux-Foundation und betreut unter dem Dach der OpenChain Reference Tooling Work Group – sollte der Community eine gute Möglichkeit bieten, ihre Arbeit systematisch zu evaluieren.
Trotzdem bliebe eine ‚Geschmäckle‘, wenn die Deutsche Telekom nur diesem Ansatz folgte. Sie würde leicht in die Rolle eines Polizisten oder Richters rutschen. Das ist nicht das, was die Telekom sein möchte. Sie möchte Community auch praktisch voranbringen. Darum hat sie bereits existierende Tools anhand von TDOSCA-Testcases evaluiert, hat Erfahrungen gemacht und Konseuqnezn gezogen:
TDOSCA und ORT …
Als erstes hat sich die DT dem Open Source Review Toolkit zugewendet, um eine Durchstichsversion zu erzeugen, die den Testcase-Input nimmt und automatisiert die Compliance-Dateien erzeugt:
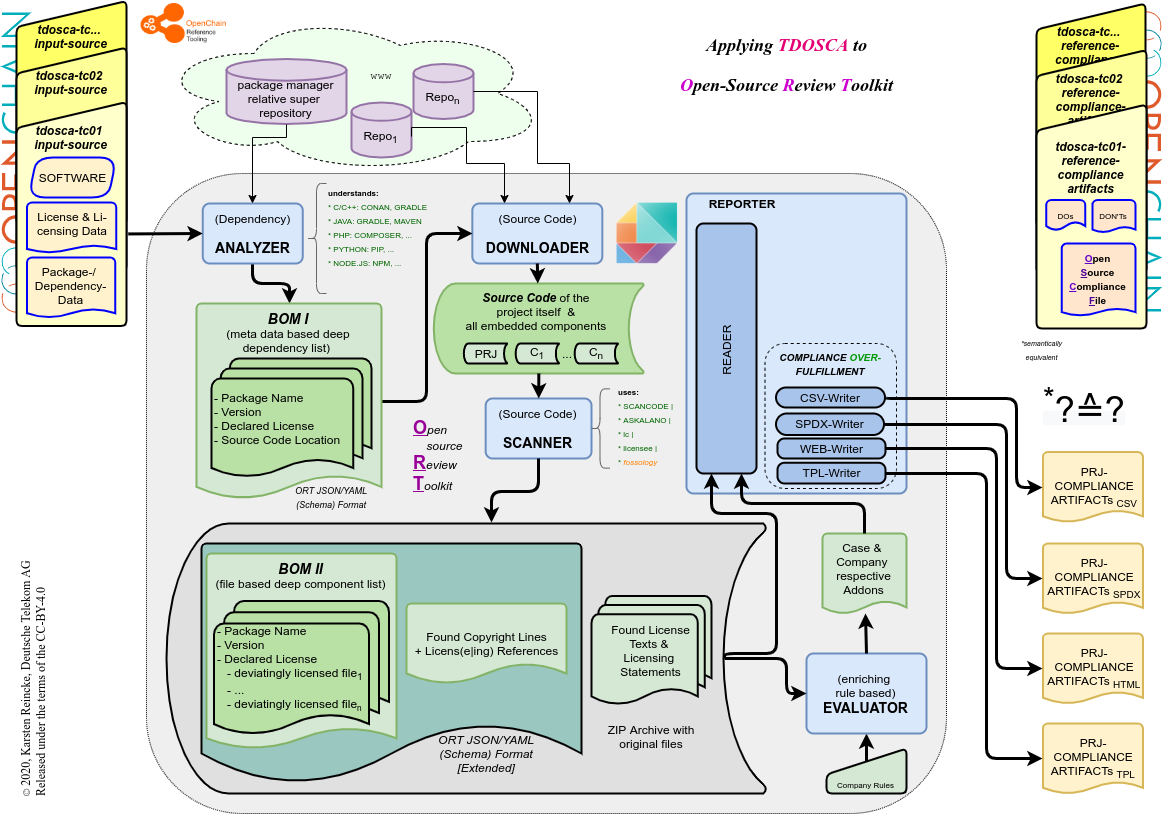
Hier sieht man die
- die 5 Komponenten, die ORT in seinem README als seine Bestandteile erähnt,
- die Art der Datenj, die sie generieren und
- die Weise, wie sie den Inhalt ihrer Vorgänger weiterverarbeiten.
Ausgehend von dieser Skizze kann man nun erläutern, …
… welche Erfahrung mit ORT
aufgelaufen sind:
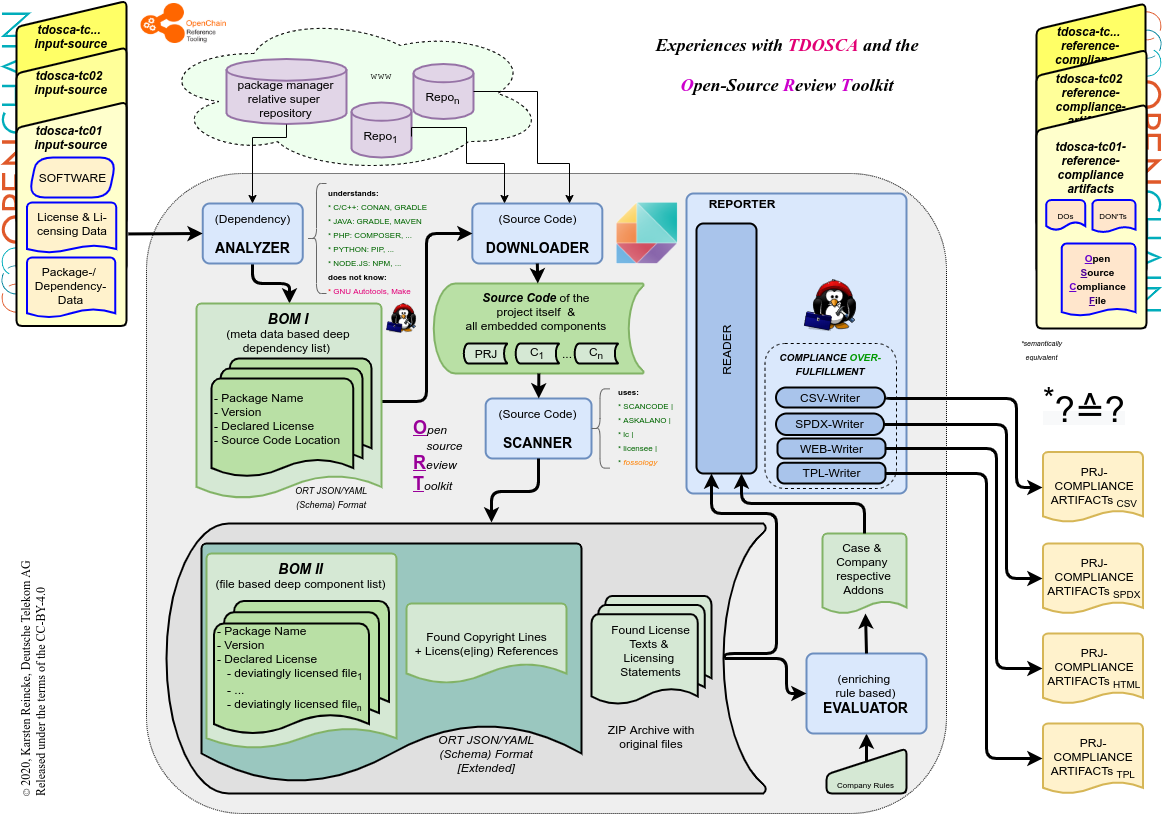
- Zunächst musste die DT akzeptieren, dass der ORT den ersten und einfachsten Test-Case nicht hat verwerten können, weil der ‚Paketmanager‘ GNU autotools noch nicht in das ORT integriert war.
- Dann musste die DT lernen, dass ORT bei der Auswertung der Daten des Paketmanagers gradle, ORT – momentan- noch nicht entscheiden kann, welches die Default-Lizenz ist.
- Und schließlich musste die DT konstatieren, das die im ORT-Reader eingebauten Standard-Templates dem Prinzip der Übererfüllung der Lizenzbedingungen folgen.
Was heißt das? Gibt man ein komplett unter der MIT lizenzisiertes Paket weiter, muss man nur diesen einen Lizenztext einschließlich des einen mit ihr verbundenen Copyrightstatements beilegen, um es lizenzkonform zu distribuieren. Tools, die dem Prinzip der Überfüllung folgen, fügen dem aber z.B. auch noch die Copyrightlines hinzu, die sie mit der GPL orientierten Suchtechnik in den Quellen gefunden haben.
Das ist ein vielfach verwendeter Ansatz. Dem Prinzip der Lizenz-Überfüllung zu folgen, ist jedoch eine problematische Strategie:
- Zum einen werden Fehler, die in den beigelegten Compliance-Artefakten gemacht werden, den Distributoren auch dann zugerechnet, wenn diese Teile gar nicht hätten mitgeliefert werden müssen.
- Zum anderen können die zusätzlich mitgelieferten Compliance-Artefakte diejenigen überschreiben oder aushebeln, die der Lizenz nach mitgeliefert werden müssen.
Glücklicherweise ist ORT modular aufgebaut und macht ihre Bestandteile konfigurierbar, was der DT erlaubt, das Tool entsprechend anzupassen:
Konsequenz 1: das ORT erweitern
- Die Deutsche Telekom plant eine Evaluierung der GNU autotools zu implementieren und an das ORT Team zurückzugeben.
- Außerdem wird sie eine Heuristik entwickeln und upstream geben, die immer die Defaultlizenz ausweist.
Konsequenz 2: die Testcases komplettieren
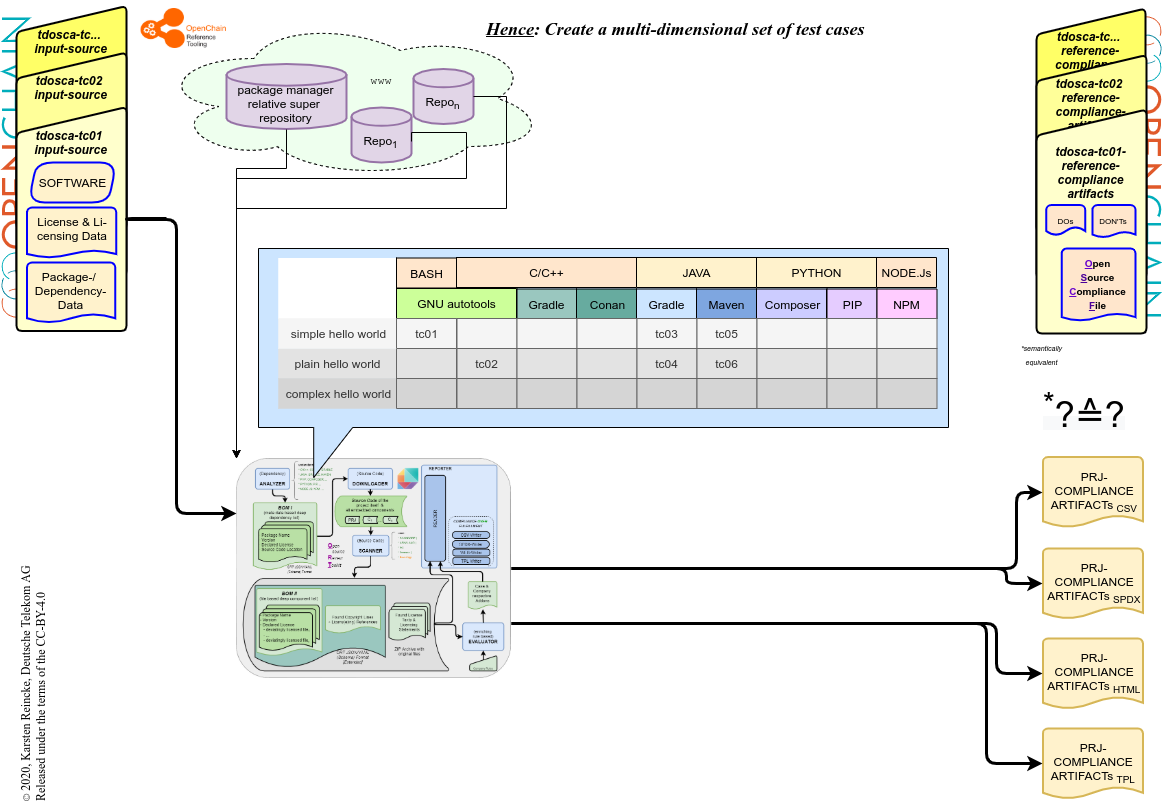
- Die DT wird ferner zusätzliche Testcase implementieren, sodass der multi-dimensionale Raum aus Complexity x Programmiersprache x Paketmanager besser abgedeckt wird..
Konsequenz 3: eine intelligente Open Source Compliance artifact knowledge engine entwickeln
- Die Deutsche Telekom AG wird schließlich eine intelligente Komponente entwickeln, in die das Wissen um Open Source Lizenzbedingungen deklarativ eingebettet ist, so dass sie es automatisiert anwenden kann. Dazu wird sie
- ihren eigenen ‚Writer‘ ins ORT einbetten
- mittels Eclipse und XText eine Domainen-spezischen Sprache in Sachen Open-Source-Lizenzen entwickeln
- und mittels Eclipse und XTend eine entsprechenden Artifact-Composer implementieren
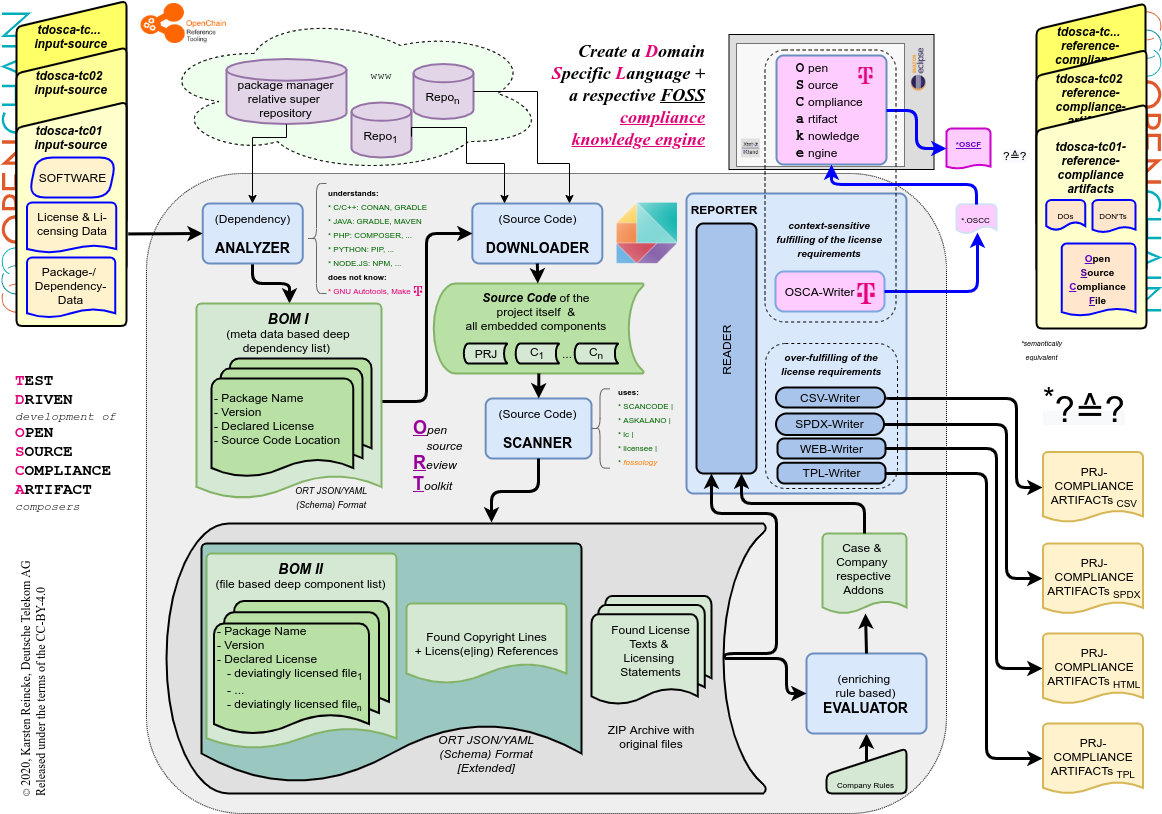
Diese neue Komponente, die auch für anderen Open Source Compliance Chains nutzbar sein soll, wird OSCake genannt und unter der Eclipse Public License 2.0 entwickelt. Die Abkürzung steht für Open Source Compliance artifact knowledge engine.
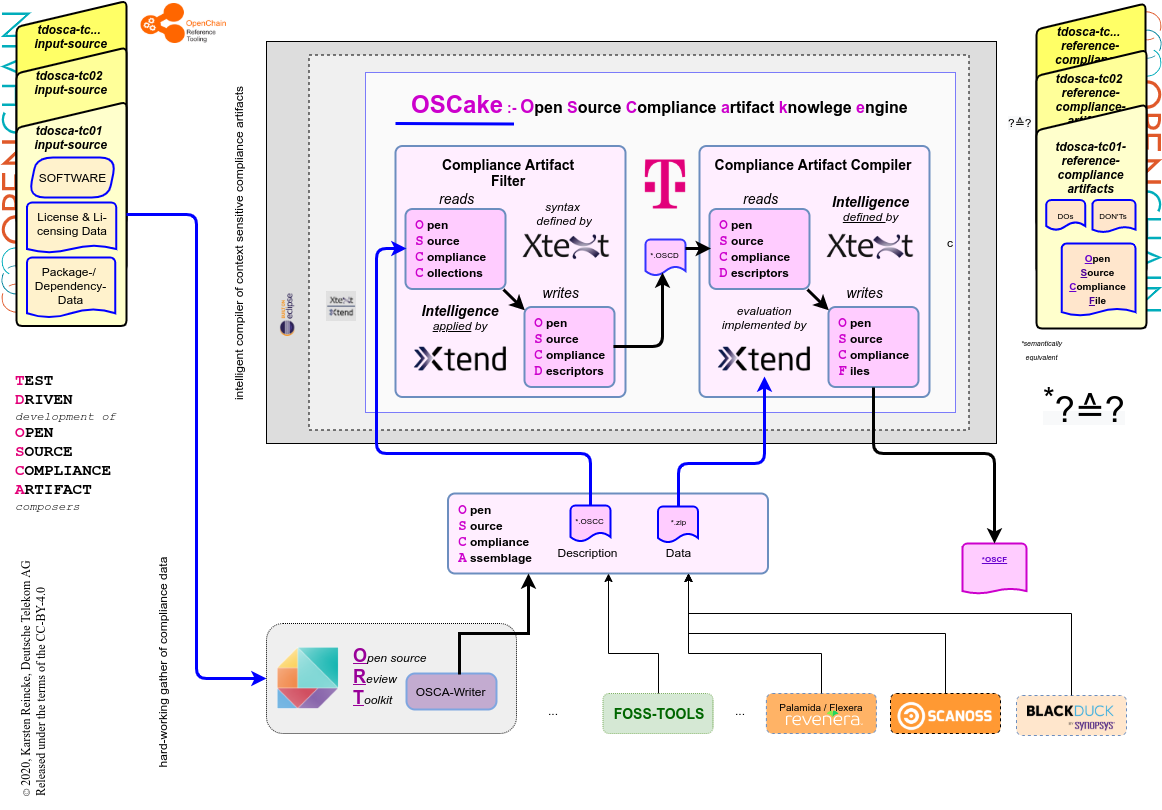
OSCake soll die Lücke schließend, die Open Source Scanner haben, die nach dem Prinzip der Lizenzüberfüllung arbeiten. Es wird Open-Source-Compliance-Collections nehmen und Open-Source-Compliance-Files liefern, die die Forderungen der Lizenzen genau erfüllen. OSCake wird eine agnostische Wissensmaschine werden, und nicht von einem spezifischen Scanning-Tool abhängen, sondern nur von einem fehlertoleranten Inputformat. Um das zu erreichen, wird OSCake mit einer bipolaren inneren Struktur arbeiten:
Fazit
TDOSCA und OSCake sind interessante Arbeitsziele, für die Deutsche Telekom AG selbst, für die Community und für andere kommerzielle Ansätze:
- DT will in der Tat eine praktisch verwendbare FOSS-Compliance-Tool-Chain aufsetzen, die automatisiert passende Compliance-Artefakte ableitet.
- DT will den manuellen Aufwand so weit als möglich reduzieren.
- Und DT wird seine Komponenten unter der Kontrolle TDOSCA verwirklichen: der Initiative zur Entwicklung von Test Driven Open Source Compliance Artifact Gatherers und Compilers
Und es ist ein besonders guter Aspekt dieser Arbeit, dass sie öffentlich passiert, unter dem Dach von Open-Chain und dessen Open Chain ReferenceTooling Workgroup.
Releated Links:
- OSLiC sources: https://github.com/telekom/oslic
- OSLiC homepage: http://telekom.github.io/oslic/
- OSLiC version 1.0.2: https://telekom.github.io/oslic/releases/oslic.pdf
- OSCAd sources: https://github.com/telekom/oscad
- OSCAd homepage: https://telekom.github.io/oscad/
- OSCAd instance: http://oscad.fodina.de/
- OpenChain homepage: https://www.openchainproject.org/
- Respective Linux Foundation project page: https://www.linuxfoundation.org/projects/security-compliance/
- Introduction into the Open Chain Reference Tooling Work Group: https://www.openchainproject.org/news/2020/03/15/openchain-reference-tooling-work-group-in-2020
- Open Chain Reference Tooling Work Group homepage: http://oss-compliance-tooling.org/
- Existing Open Source license compliance tools: http://oss-compliance-tooling.org/Tooling-Landscape/OSS-Based-License-Compliance-Tools/
- Open-source Review Toolkit: https://github.com/oss-review-toolkit/ort
- Test Driven Open Source Compliance Initiative: https://github.com/Open-Source-Compliance/tdosca
- Open Source Compliance artifact knowledge engine: https://github.com/Open-Source-Compliance/OSCake
- Open Compliance Summit 2020: https://events.linuxfoundation.org/open-compliance-summit/program/schedule/
![]() © Karsten Reincke: BERICHT vom 2020-11-28 zum Thema Compliance, FOSS, Tooling u.Ä. mit 0 Kommentaren. Veröffentlicht unter der Creative Commons Share Alike Lizenz.
© Karsten Reincke: BERICHT vom 2020-11-28 zum Thema Compliance, FOSS, Tooling u.Ä. mit 0 Kommentaren. Veröffentlicht unter der Creative Commons Share Alike Lizenz.
→ Kommentieren. | → Trackback-URI